The following guidelines define the necessary characterisitics for specifying benchmarks for RATES. It should be noted that this initial set of rules is an attempt to structure the benchmark format and it may be necessary to append, amend or expel specific rules as the reconfiurable processing field matures. Finally, we hope that some forum for discussion will be convened to esure that these guidelines fairly represent the needs of the reconfigurable community.
To ensure that the following discussion uses consistent terminology, the pertinent definitions are now given. Each benchmark contains application input and output data sets as well as a Standard Algorithm describing what functionality is to be implemented. This is the Standard Algorithm for the benchmark that may further be broken down into the individual tasks that must be performed. Each task is then described in terms of a Task Algorithm. This hierarchy is illustrated pictorially in Figure 1.
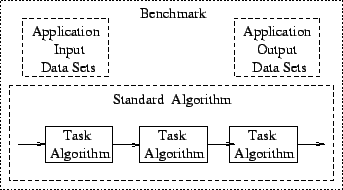
Figure 1: A pictorial hierarchy illustrating the suite's taxonomy.
Rule 1: A sequential algorithm must be given as the Standard Algorithm for each benchmark, and C source code provided as an implementation example. Source code for the reconfigurable processor must be generated based on the Standard Algorithm and not the example source code. The designer's source code implements the same Standard Algorithm demonstrated in the example source code, however, it can be parallelized and pipelined so as to obtain the best possible performance on their architecture. The example code is provided as a reference point so that the actual functionality of the benchmark can be verified. A detailed description of the Standard Algorithm specification format is given
here.
Rule 2: The specification of the Standard Algorithm must be at a functional level where the inputs and outputs to a task are detailed but the internal implementation is a black box. The objective is to describe to the user the basic components, or tasks, that should be used to implement the algorithm as illustrated in Figure 1. The tasks are described at a higher level to allow for flexibility of implementation, but a strict definition of the control flow between tasks is required to ensure that designers are executing the same Standard Algorithm.
This is sufficient information for a consistent algorithmic description. If the designer feels that the Standard Algorithm is too restrictive or does not fully utilize the processor's capabilities, the algorithm can be customized and the improvement in performance measured with respect to the standard.
Rule 3: The Standard Algorithm must always be implemented. Any modifications to this will be considered a separate Custom Algorithm. To make a reasonable comparison of performance between architectures, a common baseline is necessary. Not only must the problem be the same, but also the methodology used for its solution. When multiple different algorithms exist for solving the same problem, only one is chosen as the Standard Algorithm. Implementations of other algorithms are considered to be Custom Algorithms.
Rule 4: The input and output operands of a task must be specified in terms of type and bit width. To further restrict the interface between tasks, all input and output variable fields must be strictly specified, but the designer may choose the storage structures used to implement these variables. This ensures that everyone is working at the same minimal level of computational precision and that the application output results are consistent among processors, while not restricting the actual implementation. It should also be noted that internal temporary variables remain unspecified so as to allow even greater flexibility when mapping each task of execution to the processor.
Rule 5: Application Input and Output data sets must be supplied for reproducibility. All architectures should measure performance based on the same set of input data. This is also needed to provide a common basis for comparison. The output data sets allows for checking the correctness of the implementation.
Obviously, there is no expectation that the numerical values will be exactly the same for computationally intense applications, but the precision of the result is a measure of the correctness of the outputs. Therefore, the designer should stipulate the precision of the outputs along with the execution time. For example, if the output results from processor A are obtained in time t with 6 bits of precision whereas the results from processor B take time 2t to be generated but have 14 bits of precision, processor B could be considered a better architecture depending on the requirements.
Rule 6: The performance of the architecture as the size of the problem and/or the size of the reconfigurable fabric scales should be discussed. The intent of this rule is to provide some understanding of the behaviour of the architecture when the problem does not ``fit'' entirely on the fabric. While it is not a required measure, the results would significantly enhance the understanding of a processor's behaviour in these circumstances. All results must still show the performance of the Standard Algorithm.
Rule 7: All architectures must be evaluated with the same metrics. The process for obtaining a metric must also be clearly defined. Current metrics include:
1.
Execution Time. Execution time and the output data-bit precision are required values for each benchmark. The definition of this metric is dependent on the type of benchmark. For streaming data applications, the execution time may be measured as the throughput time for the data being processed. For applications with a definitive start and end point, the execution time is defined to be the time elapsed from when the program begins its load onto the processor until the final results are obtained.
2.
Configuration Time. Another essential metric for a reconfigurable processor is the configuration time, which is to be reported as two components. The first is the time required for initialization of the processor fabric and the second is the overhead incurred when processor execution stalls so that the fabric can be reconfigured. For reconfigurable architectures, configuration time is an important consideration as the overhead can be quite significant if not done in parallel with program execution.
3.
Power Dissipation. Power is a significant concern in reconfigurable architectures as there may be significant dynamic power dissipated when the processor is reconfigured. However, measuring power dissipation is a difficult exercise, so this metric is being discussed assuming that some researchers will focus on power issues in their architectures. It is not assumed that every designer will attempt to quantify the power dissipation of their architecture. However, for the measure to be meaningful when reported, any power dissipated during the initial configuring of the processor should also be included in the measurement.
4.
Area. The silicon area required to implement the processor may be another potential metric for use in some research. A primary consideration is that the size of a reconfigurable fabric will greatly affect the ability to parallelize and pipeline application execution. This metric should be reported as an estimate of the die area required to implement the architecture in a technology specified by the designer.
Rule 8: A well written implementation of the Standard Algorithm for execution on general purpose processors must be provided. It must be used for all performance comparisons between the reconfigurable architectures being studied and general purpose processors. Use of the Standard Algorithm again provides a common basis for comparison between the implementation on the reconfigurable processor and the general purpose processor. Requiring all performance measurements on general purpose processors to use the same code for the Standard Algorithm also provides a means for calibration between projects as it is unlikely that different projects will measure performance using the exact same general purpose processor configurations.







 Previous
Previous
